Additional Material
Missing Letters, etc.
On this page can be found material intended for publication in the print book, and which was omitted either for lack of space, or because it wasn't ready when the book went to print. In contrast to the print book, where publishing rights have been transferred to Cambridge University Press, this material remains entirely my own, and should be cited as online source: Duffield, Nigel. Additional Material (Perspectives on Psycholinguistic Theories: Raiding the Inarticulate) Http://sonatine4-rti.blogspot.com/, Accessed [date].
v is for von Humboldt (section 3)
A declarative alternative: gaps, holes and hollows
Suppose for a moment that personal grammatical competence is a de facto finite system, constrained by experience of langue, as well as by physiological and other cognitive factors (= Chomsky's third factor). What could this mean? For a start, it would imply that different speakers not only had smaller or larger grammars 'in extension' - something that almost everyone accepts - but also that their intensional grammars were smaller or larger in extent. If one believed in grammatical rules, it would mean that some speakers implicitly know more rules than others. Such a view would also imply a close, dynamic relationship between constructional frequency and grammatical acceptability: the more familiar a string of words in a particular community at a given time, the more acceptable (and easily rehearsed) that string will be. Rather than being based on some immutable and invariant biological construct, grammatical acceptability at the margins would be for the most part an ephemeral 'follower of fashion.'To work through this conjecture on neutral ground, let us return to the discussion of times-tables introduced earlier. Much earlier, in fact, in Part I of the print book. The contrast between times-tables vs. (algorithmic) arithmetic is instructive since it nicely demonstrates the difference between 'large-finite' vs. infinite systems of reckoning. It is clear that the rule systems of multiplication allow for unbounded calculation ('discrete infinity'): there is no highest product that can be derived through iterative addition. By contrast, times-tables are de facto finite systems; as was noted earlier, for me any numbers over 144 constitute uncharted space - plus the 'gaps' and 'hollows' in the system up to 144; see below. Where the two systems are extensionally equivalent, it is difficult to tell whether a given number is generated by look-up, or by rule. And if times-tables went up to 48i (2304emax) or 120i (14400emax) instead of to 12i (144emax), the extensional range of the finite system would be vast, covering the multiplication space necessary for normal life in the developed world. Arguably, a child that only acquired this finite system - supposing that children had so much time in elementary school - would cope at least as well with real-life problems of multiplication as any typically-educated child who uses a mixture of times-tables and calculation. To see this, consider Figs. 1-3:
 |
| Figure 1. Extensional Range of 10i (up to 144, for comparison) |
 |
| Figure 2. Extensional Range of 12i. |
 |
| Figure 3. Extension Range of 48i (only up to 144, for comparison) |
These tables represent what may be termed the extensional ranges (up to 144) of the intensional sets {1-10}, {1-12} and {1-48}, respectively. To seek to prevent unnecessary confusion, I'll designate intensional sets using a subscript i after the highest integer of that set; hence, {10i}, {12i}, {48i}, etc. The extensional range of a given intensional set thus includes three kinds of whole numbers. First, there are integers that are the products of all pairs of factors in that set: let us call these the 'activated numbers'; these are the yellow cells in the figures. Next, there are the prime numbers above (10 or 12 or 48, etc) up to the respective extensional maxima (100, 144, 2304). For {12i}, for example, this set comprises the twenty-nine prime numbers from 13 to 139 (inclusive). Let us call these prime numbers gaps, since they never are never activated in any product table. Gaps are the dark-blue coloured cells in the three figures. Finally, and most importantly, the extensional range also includes the multiples of primes above [10/12/48]. These might be termed the holes or hollows, since they have the same status as primes - a hole is much like a gap - until the intensional set is extended to include the relevant prime factor, when it becomes a hollow. A consequence of this is that even when a hole becomes a hollow it never attains the same level of activation as other items in the extension set.
For concreteness, consider the three integers 22, 26, and 106. For learners in decimal/metric countries whose intensional set only goes to 10 - Japanese students, for instance - all three of these numbers are 'holes'. This is because the smallest factors of 22 (excluding 1) are [2, 11]; as a result, 22 is inactive in Fig. 1. In Figure 2, however - the British (or 'Imperial Measures') set - 22 is activated: it becomes a hollow, since 2 and 11 are both included in the intensional set (12i). However, 22 is less strongly activated than a number with several factors in the intensional set, such as 36. The number 26, by contrast, remains a hole even for British readers, since it is only activated after the intensional set is expanded to include 13. (26 is a hollow in [48i]). And 106 remains a hole for all three sets of learners, since its smallest set of factors necessarily includes 53, the first prime number above 48. Notice that as well as gaps, holes and hollows, there are also 'hills' (among the activated numbers): integers with an above-average number of factors within their corresponding intensional set. The number 12, for example, has an activation value of 4 in set 1 but 6 in the other two sets, since it appears as the product of [6x2, 4x3, 3x4, 2x6] = 4, plus [12x1, 1x12] = 2 in the latter two cases. Figures 4-6 provide a clearer illustration of the topology ('hills and dales') of the extensional ranges (n<70): Figure 7 compares the three ranges directly;
 |
| Figure 4. Activated numbers in declarative memory {10i} |
 | |
|
 | |
|
 | |
|
At this point, many readers will doubtless be shaking their heads, either in condescension or bewilderment: more numerate readers will wonder how it is possible to so mess up the theory of arithmetic; the mathematically illiterate will despair that an otherwise graspable argument has been thoroughly confused by talk of integers, extensional ranges, and local maxima.
My goal here is to think about a psychologically plausible theory of calculation, and its consequences for the notion of infinity. It is obvious that a pure system of multiplication is much simpler and more elegant than anything discussed above. Pure multiplication (iterative addition) will also derive an infinite set of products: in an infinite system, there are no gaps, no holes or hollows, and information about hills goes unrepresented: it is part of 'E-multiplication', but not of 'E-multiplication'. If, however, our stored knowledge of numbers ('our multiplication grammar') is the result of declarative learning, then it is predicted that some numbers in the extensional range will be much more salient than others in implicit memory.
How should we tease apart the two hypotheses empirically? One possibility is suggested by research into lexical representation: we could look for frequency effects (as well as 'word vs. non-word' effects; see below). If particular values are stored in the same way as irregular past tense forms, for example), then we expect that more frequently-accessed items will have a lower threshold of activation, and will be preferred over less frequently-accessed items across a variety of cognitive tasks. If, on the other hand, value frequency is shown to have no measurable effects, it may be better to go with the simpler procedural model, in which our knowledge of arithmetic consists purely of the iterative function mn.
If I had not already taxed the readers' patience, this is where I would discuss new experimental results that arbitrate between two hypotheses: the experimental hypothesis (H1) that predicts a behavioural difference in participants' response to gaps, hollows and hills, and the null hypothesis (H
Discounting the numbers within the intensional set 12i (i.e. {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}, as well as numbers up to 20, the two systems make different predictions about the relative accessibility of the other integers between 21 and 144: for each decade, a declarative theory of multiplication predicts the hill numbers to be consistently more salient, and hence more frequently mentioned in texts, than the hole numbers or the primes. Table 1 lists the predicted front-runners and losers in each set. Because Google Ngram only allows a maximum of four terms in any comparison, I'll consider the predictions only for the even numbers within each decade:
 |
| Table 1. Predicted 'winners' and 'losers': relative salience in declarative integers. |
There are a variety of different ways of testing this prediction, including simple t-test comparison of the incidence of 'predicted winners' vs. 'predicted losers', or ANOVA, treating Series (decade) and Predicted Salience as independent variables (see below), or chi-squared analyses of the distributions within each series. Whatever statistical test is employed, the null hypothesis (H0) is the same: any differences observed between 'predicted winners' and 'predicted losers' should be due to chance; there should not be a statistically significant skewing in favour of the predicted 'winners'. And in every case, the alternate hypothesis is one-tailed: more than merely predicting a distributional contrast between the two groups, the experimental hypothesis predicts a specific direction of bias - as the name suggests, 'winners' should occur in texts significantly more frequently than 'losers.'
Once more, Google Ngram offers a perspicuous way of probing for differences, since it delivers an instant time-series analysis: if one number turns out to be consistently more frequently mentioned in every year's publications from 1800-2000, it is reasonable to conclude that this pattern is not due to chance; for any given year, the probability might be 50% (0.5), but if if the same pattern is observed every year for 200 years, the probability that this is due to chance is remarkably small. Naturally, this does not prove that the alternate hypothesis is correct, but it does at least suggest that there is a case to answer.
And the winner is…
 |
| Figure 8. Observed winners and losers (20s) |
 | |
|
 | |
|

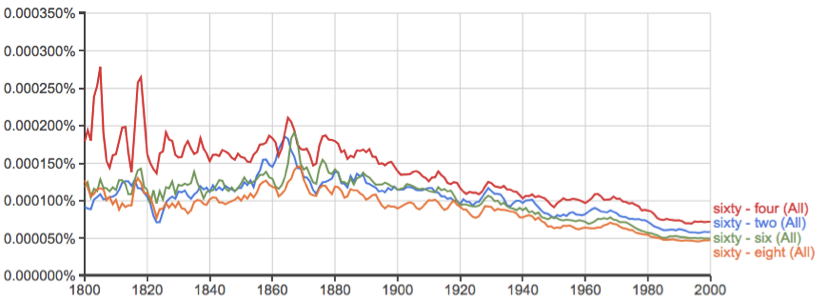

 | |
|
Figures 8-10 show the Google Ngrams for series 20, 30, 40, respectively; Figure 10 presents the results of the remaining decades (50-80).
Among the predicted losers, the only unexpected number is 52, which is the most frequent number in the fifties (despite being 'a hole') until one reaches 13i. (Mathematically, the popularity of 52 is especially surprising, since it is a wonderfully named 'Untouchable Number': 52 is one of the few integers under 100 that cannot be expressed as the sum of the proper divisors of any positive integer, including the untouchable number itself. The other Untouchable Numbers in the range are 1, 5, 88, and 96. Mathematics is amazing.) Yet there is no great mystery here, as the numerically unsophisticated will have already realized: 52 is the number of weeks in a year, as well as the number of cards in a full deck (such as I am still shuffling with, just about...)
Otherwise, the charts bear out the H1 predictions nearly perfectly. To wit, in Figs. 8 and 9, the predicted winners are approximately twice as frequent as the predicted losers in every publication year from 1800-2000; in Figures 9 and 10, years ending in ~8 have a lower frequency of occurrence than other even numbers (38/58/68/88) in their respective decades, except for 48, which is a predicted winner; likewise for the numbers ending in 6 (46/56/66/86), except for 36, again a predicted winner; 72 is, as predicted, significantly more frequently mentioned than any other even number in the 70s.
George Orwell didn't just happen to name his novel 1984: mathematically, it might as well have been 1983 or 1988, but it seems a reasonable bet that these latter dates never came to (his) mind.
A similar pattern of results obtains if one compares the two groups synchronically by two-way ANOVA, using as the dependent measure the total number of hits in Google Books (on 7/18/15). A glance at Table 2 below suggests that the difference between predicted winners and losers should be statistically significant: in every decade, winners do better than losers, sometimes substantially better (24, for example, has nearly twice the number of hits of the next highest even number in the twenties series); and there is no series where losers score a higher number of hits than winners.
 |
| Table 2. Observed Winners and Losers (Google Books count) |
It is perhaps surprising, then, that the effect is not statistically reliable: a two-way ANOVA with series and W/L as independent variables reveals a significant main effect of series (p < .05) - lower decades attracting higher numbers of hits - but no main effect of W/L. The reason for this is the huge heterogeneity of variance, shown by the error bars in Figure 12: essentially, the 'winners' are more different from each other than they are from the 'losers' as a group. (Also the very low number of data points, of which more anon). Returning to our previous analogy, the 'hills' (24, 36, 48) are so high that they obscure the differences between activated cells -- the other 'winners' -- and the losers. We can address this by excluding the hills (L/M/H < 3), and re-running the ANOVA, this time crossing series with L/M. Notice that this is not simply excluding awkward results: the H category was determined in advance on the basis of Fig. 2 above. It happens that this corresponds exactly to the outliers in the results, but that is just a good prediction. Once these numbers are excluded, however, the predictions of the experiment are perfectly borne out: there is a clear main effect of series (p. < 0.001) and of L/M (=losers vs winners). Notwithstanding the methodological issues concerning the validity of using ANOVA for such a small number of measures per level, the fact that these synchronic results align so closely with the diachronic time series data suggests that it is justified to reject the null hypothesis, and to conclude that some numbers are indeed more salient than others (in other words, that hollows are a real psychological phenomenon):
 |
| Figure 12. Unreliable evidence: the heterogeneity of winners |
Having explored the times-tables more than is healthy, let us return to grammar. The discussion of numbers, including the distinctions between intensional and extensional sets, as well as those among gaps, holes, hollows and hills, raises the possibility that information about syntactic structure might be represented in a similar way, through a varied mixture of learned constructions, sentence fragments, ad hoc rules and deterministic algorithms, the last being the least often used. This possibility is more consistent with the case studies presented in Part 2 of the print book than any purely derivational procedure. Of course, I am not suggesting any direct relationship between English grammar and twelve-times tables: it is finally only a metaphor. Yet it does not seem completely absurd to think of sentences being related in terms of their 'common divisors' (aka constituent phrases), with those divisors themselves treated as primitives (i.e., members of the intensional set).
So, just as we can think of 12 (12i) either as an unanalyzed number or as the product of 2 and 6 or 3 and 4 (6e, 4e), so we can think of a simple transitive clause either as a wholly unanalyzed construction S12 or as a NP4-VP8 sequence, or as an NP4-V2 NP4 sequence, but not, for example as an *VP8(=NP-V)-NP4 sequence (unless, that is, you happen to speak Malagasy or another VOS language, in which case VP8-NP4 is the normal linear constituency of S12). Complex sentences involving clausal complements ('She wonders whether he has lost his mind') might be addressed directly, as a multiple of 12, say S36, or as the activation of its constituent parts (S12 [he has lost his mind}; VP8 [whether…mind, lost his mind], NP2 [she, he, his, his mind], etc). Recursive procedures of some kind will still be required, but only (literally) to 're-iterate' strings: in other words, simple linear recursion (SLR). And in such a system, just as in times-tables, procedural rules would only kick in after declarative knowledge has been exhausted: just as we don't need to add 1 to itself fifty-four times to derive 54, or (come to that), 9 to itself six times, so it is unnecessary to 'start at the very beginning…' - from the numeration up - every time we want to derive a complete sentence. Often 'it's [not] a very good place to start.' Instead, we might analyze and build sentences by addressing the sequences we already have stored in our intensional set (personal competence).
Parametric variation can be understood, on this approach, in terms of different patterns of linear constituency, within intensional units: like times-tables (recall the child who knows six times nine, but is unsure of nine times six) each unit encodes the canonical linear order of its constituent. Thus PP4 for an English speaker might have a canonical P2-NP2 shape; for a Japanese speaker the order of elements is reversed. Language acquisition would then involve the gradual expansion of the intensional set - the set of pre-compiled phrases, and a retreat in the importance of rules (for normal purposes).
It is pointless to develop this idea any further in this chapter. For one thing, it will already be clear that the two-dimensional approach of the times-tables is grossly inadequate to describe the complexity of natural language syntax. There is no sense in which simple nouns, for example, are more basic than verbs, adjectives than prepositions, such that we could say that noun = 2, preposition = 5, verb = 3, or any other purely linear correspondence; nor, to take another example, are intransitive verb-phrases containing many adjunct modifiers more or less complex than transitive verb-phrases with small clause complements. It seems much more plausible that each syntactic category should be assigned its own vector, or dimension, all of these dimensions connected and reinforced through patterns of use, with more or less complex sentences represented as the sum of patterns of activation along particular dimensions. Multiplication is also a questionable metaphor: simple addition (of pre-compiled phrases or numbers) is probably a closer analogy. In any case, the main point of the exercise was not to demonstrate the accuracy of the analogy, but to create 'reasonable doubt', by showing that what can in principle be understood as a purely abstract procedural system displaying discrete infinity - the product of any two integers is always a whole number (= discrete), there is no highest product (= infinity) - may in fact be represented in the mind of a 'native-calculator' as a de facto finite system with holes and gaps ('times-tables plus').